



















































You must be wondering why data has become so important these days. A decade ago, the amount of data generated was quite less and it was not crucial for every business. Today, however, we have high computational power, and we can store and process a massive amount of data to harness meaningful insights from them. This process of collecting raw data and transforming it into valuable conclusions is generally known as data science. It is an interdisciplinary field that encompasses a number of concepts like data cleaning, data modeling, data analysis, data visualization, and so on.
If you don’t know data science from scratch, you may get stuck when starting with a new data-related project. One of the common reasons why you may not move ahead in a project seamlessly is not following the steps involved in the data science life cycle. Though the steps followed in the data science life cycle are not as well-defined as a software development life cycle, you need to be clear with the general workflow. Whenever you take any online data science course, like Data Science with R Programming, it will first explain to you the data science life cycle as moving ahead with other topics then becomes easier.
Let us understand the general steps followed by every organization as part of the data science life cycle.
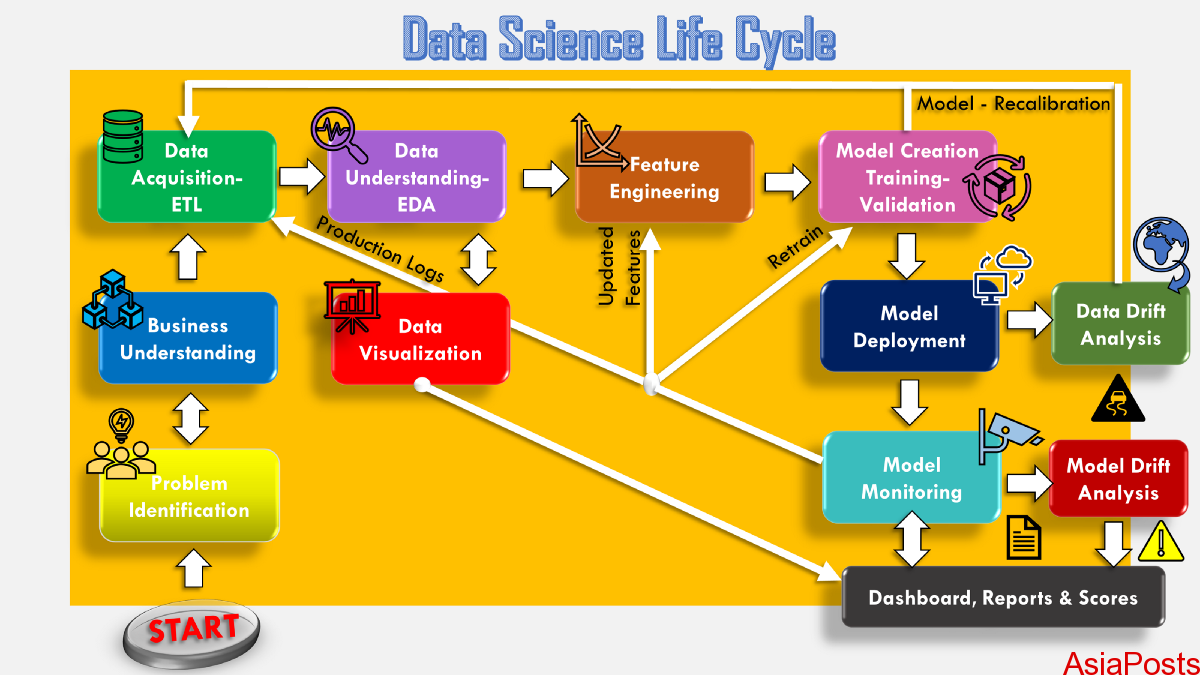
The Data Science Life Cycle
You must note that no two organizations will follow precisely the same steps for their data science projects. However, they will come up with a similar trajectory and will have at least some steps common with other data science efforts. Let’s discuss those steps.
Understanding the client requirements
Every data science project has a goal to achieve which is decided as per the client’s requirements. In other words, a client is trying to solve a problem through data science and thus gives the requirements for the solution they want to be developed. So the first task is to understand the client requirements clearly and set the goals of a data science project.
Data collection
After the goals are set, companies identify which data sets are necessary for answering the questions or solving the given client problem. They collect the information regarding the sources from where data needs to be collected. In this process, data engineers help in mining the necessary data using advanced ETL (extract, transform, load) tools and create databases so as to meet the needs of data scientists in the next steps.
Data cleaning
After collecting the data and integrating it, data cleaning is the next step followed. The collected data may have corrupt values, duplicate entries, inconsistent values, or missing values. So, the quality of the data is improved and converted into a single format so that running them for further process is feasible. If the data is not cleaned, it may lead to inaccurate results in the consecutive steps. At the end of this step, the data is ready for analysis.
Exploratory data analysis
Exploratory data analysis or EDA plays an important role at this phase as summarization of structured (cleaned) data assists in finding the patterns, outliers, and anomalies in the data. Exploratory data analysis involves variable identification, missing values treatment, outlier treatment, variable transformation, and variable creation.
Model Building
This is the major step where data scientist contributes their efforts as this step involves selecting a suitable kind of model based on the problem at hand (classification, regression, or clustering). Data scientists use either statistical analysis or machine learning techniques for building the model. You give input data to the model, train it, and check if it is giving the desired output. The process is continued in iterations until the model gives minimal errors and describes the data accurately.
Data Analysis
After building the model, data analysis is performed to identify hidden trends and correlations to gain valuable insights. The problem that the organization has identified at the beginning, data analysis is what can help you find answers to them. Actionable insights from the model demonstrate how data science has the power to perform predictive analytics and prescriptive analytics. Some organizations may visualize the data after this step to get a graphical representation of the trends and patterns and show them to the stakeholders.
Model Deployment
When an organization takes the model through a rigorous assessment, they finally decide to deploy it in a suitable structure and channel. Basically, this is the last step in the data science life cycle. Whatever the form of the data model created, it must be exposed to the real world. Capturing the feedback given by the actual customers can help data scientists improve the model further that meets their expectations.
The above-mentioned steps are what followed by organizations in general and there are chances that the actual steps may vary from organization to organization. Knowledge of all the above steps will showcase that you are familiar with the data science life cycle and are ready to become a part of the data science project. You can take up an online data science course to build a strong foundation in this domain.






{kind=link}